 打印本文
打印本文  关闭窗口
关闭窗口 原生四核心处理器:
一直以来AMD都在向外宣传该公司将要推出的Barcelona处理器将会是世界上首款原生四核心处理器,而intel公司当前的四核心处理器实际上是两个双核心处理器拼起来的。原生四核心将会带来更好的性能提升比例,同时在通过缓存进行数据交换的速度也将会更快。
为了证明这一点,我们使用Cache2Cache进行了测试(实际时间为双倍时间):
|
Cache 同步 (ns) | |||
|
|
相同核心,不同封装 |
不同核心,相同封装 |
不同核心, 不同封装 |
|
Opteron 2350 |
152 |
N/A |
199 |
|
Xeon E5345 |
59 |
154 |
225 |
|
Xeon DP 5160 |
53 |
- |
237 |
|
Xeon DP 5060 |
201 |
N/A |
265 |
|
Xeon 7130 |
111 |
N/A |
348 |
|
Opteron 880 |
134 |
N/A |
169-188 |
从测试结果来看,AMD的原生四核心与1级缓存进行数据交换需要用时76ns。这个结果应该不坏,但是却比不上Xeon处理器二级缓存26-30ns的。如果是0号核心与3号核心进行数据互传,那么Intel所需时间不到77ns,而 Opteron用时为76ns。因此复杂的三级缓存设置会对原生四核心设计带来负面影响,不过这我们将会在以后进行的更复杂的测试中进行研究。
存储系统:
AMD公司这一次对新款 Opteron 处理器的内存性能进行的有效的提升,在该处理器上也许只有1级缓存基本没有什么变化:与K8处理器的一级缓存一样都为2路64KB。与目前所有的处理器一样,Opteron 2350同样能够在每一个时钟循环进行16 bytes传输。
|
Lavalys Everest L1 带宽 | |||||
|
|
读取 (MB/s) |
写入 (MB/s) |
复制(MB/s) |
Bytes/循环 (读取) |
延时 (ns) |
|
Opteron 2350 2 GHz |
32117 |
16082 |
23935 |
16.06 |
1.5 |
|
Xeon 5160 3.0 |
47860 |
47746 |
95475 |
15.95 |
1 |
|
Xeon E5345 2.33 |
37226 |
37134 |
74268 |
15.96 |
1.3 |
|
Opteron 2224 SE |
51127 |
25601 |
44080 |
15.98 |
0.9 |
|
Opteron 8218HE 2.6 GHz |
41541 |
20801 |
35815 |
15.98 |
1.1 |
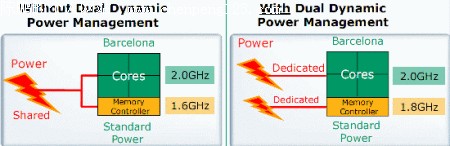
在AMD公司过去处理器产品上,二级缓存的带宽一直是一个弱点。回首K7雷鸟的时候,AMD只是简单得将二级缓存放进核心内。结果就是通过L2与L1的64bit的传输带宽只能够在每个时钟循环实现2.4 至 3 bytes的传输。虽然在K8架构上传输性能提升了50%,但是依然要远落后于intel公司的二级缓存。但是在Barcelona架构下,一级缓存的数据传输带宽将可以达到 256-bit:
|
Lavalys Everest L2 带宽 | |||||||
|
|
读取(MB/s) |
写入 (MB/s) |
复制 (MB/s) |
Bytes/循环 (读取) |
Bytes/循环 (写入) |
Bytes/循环(复制) |
延时 (ns) |
|
Opteron 2350 2 GHz |
14925 |
12170 |
13832 |
7.46 |
6.09 |
6.92 |
1.7 |
|
Dual Xeon 5160 3.0 |
22019 |
17751 |
23628 |
7.34 |
5.92 |
7.88 |
5.7 |
|
Xeon E5345 2.33 |
17610 |
14878 |
18291 |
7.55 |
6.38 |
7.84 |
6.4 |
|
Opteron 2224 SE |
14636 |
12636 |
14630 |
4.57 |
3.95 |
4.57 |
3.8 |
|
Opteron 8218HE 2.6 GHz |
11891 |
10266 |
11891 |
4.57 |
3.95 |
4.57 |
4.6 |
|
对比 | |||
|
|
Bytes/循环 (读取) |
Bytes/循环 (写入) |
Bytes/循环(复制) |
|
Barcelona VS Santa Rosa |
63% |
54% |
51% |
|
Barcelona VS Core |
-1% |
-5% |
-12% |
|
Santa Rosa VS Core |
-39% |
-38% |
-42% |
相对于 K8,Barcelona的带宽提升幅度大约在50%-60%。这次我们同样也测试了15个循环的延迟,可以看到现在AMD的二级缓存性能与Intel Core缓存差不多。
接下来让我们看看这一次Barcelona在内存性能上究竟可以带来什么样的提升,首先进行的是Lavalys Everest 4.0.11:
|
Lavalys Everest 内存测试 | |||||||
|
|
读取 (MB/s) |
写入 (MB/s) |
复制 (MB/s) |
Bytes/循环 (读取) |
Bytes/循环 (写入) |
Bytes/循环 (复制) |
延时(ns) |
|
Opteron 2350 2 GHz |
5895 |
4463 |
6614 |
2.95 |
2.23 |
3.31 |
76 |
|
Dual Xeon 5160 3.0 |
3656 |
2771 |
3800 |
1.22 |
0.92 |
1.27 |
112.2 |
|
Xeon E5345 2.33 |
3578 |
2793 |
3665 |
1.53 |
1.2 |
1.57 |
114.9 |
|
Opteron 2224 SE |
7466 |
6980 |
6863 |
2.33 |
2.18 |
2.14 |
58.9 |
|
Opteron 8218HE 2.6 GHz |
6944 |
6186 |
5895 |
2.67 |
2.38 |
2.27 |
64 |
|
Lavalys Everest 对比 | ||||
|
|
Bytes/循环 (读取) |
Bytes/循环 (写入) |
Bytes/循环 (复制) |
延时(ns) |
|
Barcelona VS Santa Rosa |
26% |
2% |
54% |
29% |
|
Barcelona VS Core |
92% |
86% |
111% |
-34% |
|
Santa Rosa VS Core |
74% |
99% |
44% |
-44% |
凭借更深的缓存以及更富裕的 2x64-bit互通有效得提升了读取带宽,不过写入缓存则有一些负面影响。但是这不会有什么实际影响,毕竟只。有很少的应用会专门等待这个较长的时间,这里可以注意到每一个循环复制带宽提升了大约54%。
因此借助更大的二级缓存、内存带宽以及更低的延迟,第三代 Opteron处理器也许是你能找到的内存性能最高的处理器产品。接下来就让我们看看如此出色的内存性能究竟在实际的应用中会为我们带来什么样的好处
打印本文 关闭窗口